
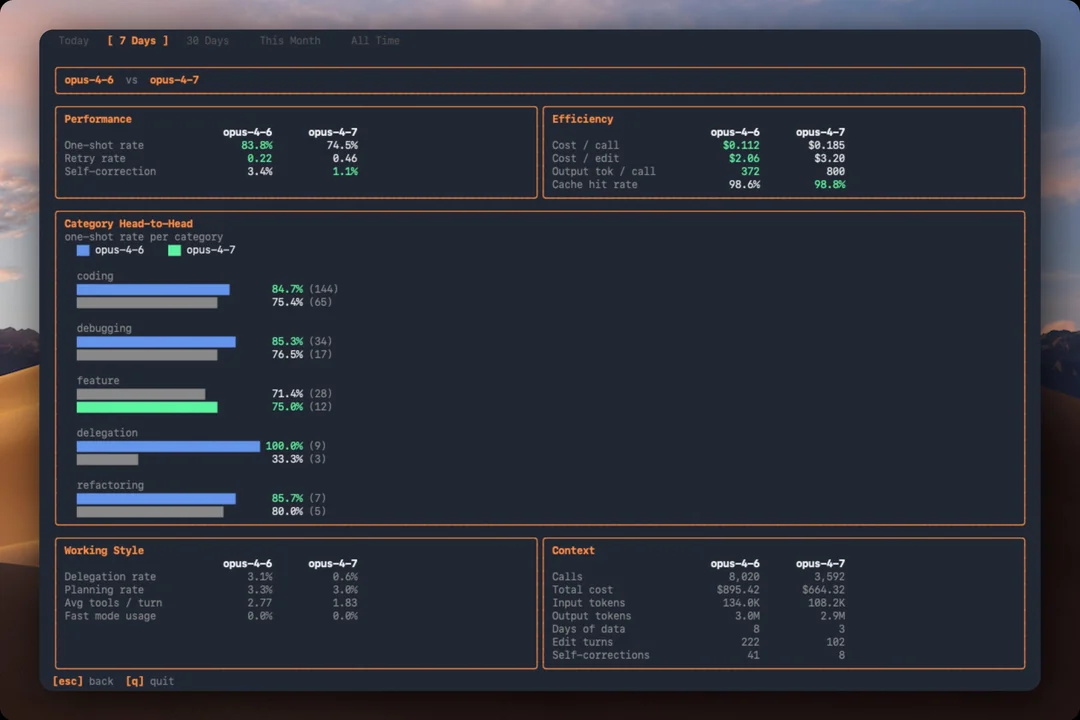
실제 사용 데이터 기준 Opus 4.7은 4.6보다 첫 시도 성공률과 코딩·디버깅 지표는 낮고, 출력량과 비용은 더 큰 편.
아직
4.7데이터는 초반이지만, 예상 밖인 지점들이 몇 가지 있었음.4.7,4.6모두maxeffort 로 진행내 세션에서는
4.7이4.6보다 첫 시도에 맞히는 비율이 낮음.one-shot rate: 74.5% vs 83.8%
edit당 retry: 0.46 vs 0.22로 거의 두 배
4.7은 call당 출력도 훨씬 많아 비용 체감이 커짐.output token/call: 약 800 vs 372
cost/call: $0.185 vs $0.112
task type별로 보면 coding과 debugging은
4.7쪽이 약해 보임.coding one-shot: 84.7%에서 75.4%로 하락
debugging one-shot: 85.3%에서 76.5%로 하락
feature work는
4.7이 75% vs 71.4%로 살짝 높지만 sample이 작음delegation은 100% vs 33.3%로 차이가 크지만,
4.7쪽 sample이 3개뿐이라 아직 크게 의미 부여하긴 어려움
4.7은 turn당 tool 사용도 더 적고 subagent 위임도 거의 하지 않음.tools/turn: 1.83 vs 2.77
subagent delegation: 0.6% vs 3.1%
style 차이인지, sample이 작아서 생긴 차이인지는 아직 불확실
몇 가지 주의 사항이 있음.
4.7데이터는 약 3일치, 3,592 calls4.6데이터는 약 8일치, 8,020 calls일부 category는 예시가 몇 개 안 됨
사용량이 더 쌓이면 수치는 바뀔 수 있고, 어떤 작업을 하느냐에 따라 결과도 달라질 가능성이 큼
지표 의미
Metric | What it measures |
|---|---|
One-shot rate | retry 없이 성공한 edit turn 비율 |
Retry rate | edit turn당 평균 retry 수, 낮을수록 좋음 |
Self-correction | model이 자기 실수를 스스로 잡아낸 turn 비율 |
Cost / call | API call당 평균 비용 |
Cost / edit | edit turn당 평균 비용 |
Output tok / call | call당 model 출력량, 즉 얼마나 장황한지 |
Cache hit rate | input 중 cache에서 온 비율과 새로 들어온 비율 |
댓글을 남기려면 로그인이 필요합니다.
로그인 후 이 페이지로 돌아와 바로 댓글을 남길 수 있습니다.