
codex 로 speech-to-text 서비스를 만드는 예제를 따라 하려다가 보니, 음성파일이 필요했습니다.
유튜브에서 뉴스 영상을 음성 소스로 사용하려고 보니 녹음을 할 수가 없습니다. (원래 윈도우 녹음기로 되는 것 아니었나?)
결국 codex로 윈도우 녹음기를 만드는 걸 먼저 했습니다.
파이썬으로 구현되었고 UI 라이브러리는 tkinter 라는데 미니멀하고 나쁘지 않네요.
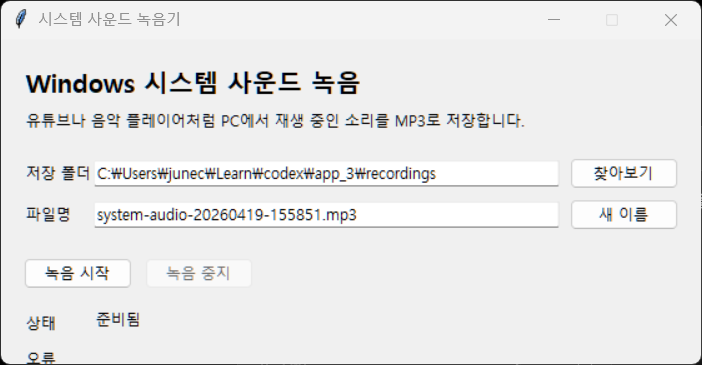
.
.
.
.
.
# Windows 시스템 사운드 녹음기 계획
## Summary
Python 기반의 작은 Windows 데스크톱 앱을 만든다. 기본 목표는 PC에서 재생 중인 시스템 사운드(예: 유튜브, 음악 플레이어)를 루프백 캡처로 녹음하고, 사용자가 시작/중지한 뒤 바로 `MP3` 파일로 저장하는 것이다.
## Key Changes
- 앱 형태는 `tkinter` 기반의 단일 창 GUI로 구성한다.
- 화면에는 최소한 `저장 폴더`, `파일명`, `시작`, `중지`, `상태 표시`를 둔다.
- 오디오 입력은 마이크가 아니라 Windows 기본 출력 장치의 루프백 캡처를 사용한다.
- 캡처 계층은 Windows 시스템 오디오 루프백을 지원하는 Python 라이브러리를 사용한다.
- 저장 파이프라인은 `PCM/WAV 버퍼 수집 -> 녹음 종료 시 MP3 인코딩 -> 최종 파일 저장` 구조로 잡는다.
- 장시간 녹음 중 UI가 멈추지 않도록 녹음은 백그라운드 스레드에서 처리한다.
- 녹음 중 예외가 나면 사용자에게 원인을 보여주고, 부분 파일 정리 정책을 명확히 둔다.
- 첫 버전의 공개 인터페이스는 GUI만 제공하고, CLI 모드는 포함하지 않는다.
## Implementation Notes
- 의존성은 두 축으로 잡는다: 시스템 오디오 캡처용 Python 패키지, MP3 인코딩용 `ffmpeg` 또는 동등한 인코더.
- 앱 시작 시 필요한 의존성이 없으면 감지해서 안내 메시지를 보여주고 실행을 중단한다.
- 기본 파일명은 현재 시각 기반으로 자동 제안하고, 확장자는 `.mp3`로 고정한다.
- 샘플레이트와 채널 수는 기본 출력 장치 설정과 호환되는 안전한 기본값을 사용한다.
- 첫 버전에서는 편집 기능, 예약 녹음, 트레이 상주, 시스템 사운드+마이크 믹스는 제외한다.
- 저작권/플랫폼 정책 이슈를 피하기 위해 DRM 보호 콘텐츠 캡처 우회 기능은 다루지 않는다.
## Public Interfaces / Types
- GUI 상태 모델에 다음 필드를 둔다: `is_recording`, `output_dir`, `filename`, `status_text`, `error_text`.
- 녹음 서비스 계층은 최소한 `start_recording()` / `stop_recording()` / `save_mp3()` 책임으로 분리한다.
- 설정은 파일로 복잡하게 저장하지 않고, 첫 버전에서는 실행 중 메모리 상태만 관리한다.
## Test Plan
- 유튜브 재생 중 녹음을 시작하고 중지했을 때 `MP3` 파일이 생성되는지 확인한다.
- 무음 상태에서 녹음했을 때도 앱이 오류 없이 빈 오디오 파일 또는 매우 작은 결과를 처리하는지 확인한다.
- 녹음 중 창이 응답 불가 상태가 되지 않는지 확인한다.
- 저장 폴더가 잘못되었거나 쓰기 권한이 없을 때 사용자 친화적인 오류가 표시되는지 확인한다.
- 의존성이 없을 때 앱이 크래시하지 않고 설치 필요 메시지를 보여주는지 확인한다.
- 연속으로 `시작 -> 중지 -> 다시 시작` 했을 때 상태가 정상적으로 초기화되는지 확인한다.
## Assumptions
- 대상 OS는 Windows다.
- 추가 패키지와 MP3 인코더 설치를 허용한다.
- 첫 버전은 “기본 출력 장치에서 재생되는 소리” 기준으로 동작하면 충분하다.
- 결과물은 한국어 사용자가 바로 쓸 수 있는 간단한 로컬 GUI 앱으로 한다.
댓글을 남기려면 로그인이 필요합니다.
로그인 후 이 페이지로 돌아와 바로 댓글을 남길 수 있습니다.