사운드에 본질을 아나요

hyperx cloud 이어버드 ii는 임피던스가 65옴 이어서 소리가 앵간하여요.
소리는 주파수로 전달되지만 표현 방식은 또 다른 의미를 가지는 거여요.
a e i o u 는 Vowel Sounds로서 모음 소리이어요. 이거는 발음에 중요한 역할을 하는 소리이저. 예컨데 말하는 피아노 1.link 는 모음 소리를 가지지 아니하여서 사람이 소리를 유추하여서 이해하여야 하는거여요. 이렇게 되면 일반적으로 의사소통이 앵간해지겟쩌. 또 다른 영상 2.link 을 살펴보면 단어에 소리를 일차 원적으로 단편화 하여서 유츄하는 것도 앵간하게 되는 경우가 이쩌.
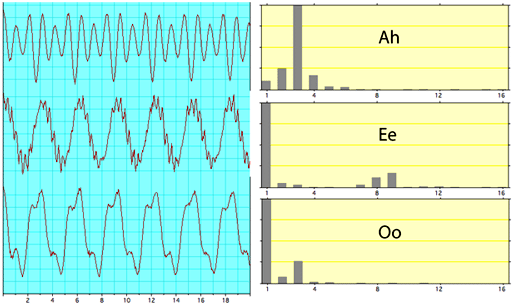
source: 3.Vowel Sounds
소리는 일반적으로 생존에 중요한 역할을 해요. 예를 들면 천둥이 심하게 치려고 하는 날 마침 휴식 중인 나른한 멈뭄이가 찬라에 생긴 천둥 소리를 듣고 놀라서 난리가 심하였쩌. 무서운 소리에 반응이 아주 빠른 거여요. 이거는 과자 포장을 뜯는 찰나에 소리에 놀라지 않아요. 동물확대 넘모 커여여 4.link
솔까 위에 오디오 파형을 순수하게 ai 모델에 넣어서 구동하면 딥 신경망이 특징을 분류하여서 해시 처럼 일정한 일정한 시그널을 만들어 낼건데요. 이케 하면 h100 하나로 어렵고 클러스터를 만들어서 아주 많은 데이터를 수확하여야 해요. 이러면 전기료 .. 망해요. 이럼 결과적으로 표본을 줄이는 방법을 사용해야 하는 거여요. 목소리는 주로 300hz 언저리에서 표현이 된다고 하는데 이럼 음계 라-에 해당하는 440hz 보다 작다는 거 아니나요. 일반적으로 소리에는 44100hz 48000hz 처럼 이런 단위를 사용해요. 22500hz .. 인터넷에 48000 과 44100 샘플링에 대하여 논쟁이 아주 많아요.
사람에 청각은 일반적으로 20 - 2만hz 정도로 보는 관례가 있는데 이럼에도 목소리는 이케 나이트코어 5.link 내지는 칩툰 6.link 처럼 높았다 하더라도 1000hz 정도로 보아요. 이럼에도 불구하고
예컨데 chippettes 노래를 고퀄리티로 뽑아내려고 한다면 남자 가수가 반토막난 bps로 느리게 가사를 읇어서 2배속으로 재생하면 되어요. 반주와 영상은 믹싱과 더빙을 하면 되겠쩌.
이케되는 거를 참고하여서 샘플링에 변화가 생기면 머가 달라지는 거나요. 22500hz라 하더라도 실질적인 차이를 알기 어려워요. 실제로는 타악기 소리가 제거되거나 변형되어요. 이 소리는 파형은 일반적으로 앵간하게 높아서 손실이 생기는 것이저. 11025hz로 떨어뜨리면 소리는 더 심하게 앵간해저요.
특이점이 무엇인지 아시나요. 이케 보컬 전용 음원 link 있는데 샘플링이 떨어지면 a e i o u 기초 발음에 지대한 손실이 되어서 앵간해져요. 예시에 샘플링은 44100hz에서 1/40로 1102 이어요. 이럼에도 1/10인 4410hz에서는 보컬이 온전하게 유지되어쩌. 목소리는 일반적으로 440hz보다 적을거이지만 발음을 합성하는 과정에서 a e i o u 특히 모음이 아닌 자음들은 순간 마다 찰나에 독특한 발음을 만들어내어서 주파수가 뛰는 특징이 나요.
이런 특징을 잘 반영하여서 엔코더를 만들면 ai연산에 필요한 데이터 수를 획기적으로 줄이는 수가 있겠쩌. 주말에 rnn 같은 모델을 조사하려고 하였는데 이거보다 앞에 해결하여야 하는 문제가 났어요. 어떡하나요.
댓글을 남기려면 로그인이 필요합니다.
로그인 후 이 페이지로 돌아와 바로 댓글을 남길 수 있습니다.